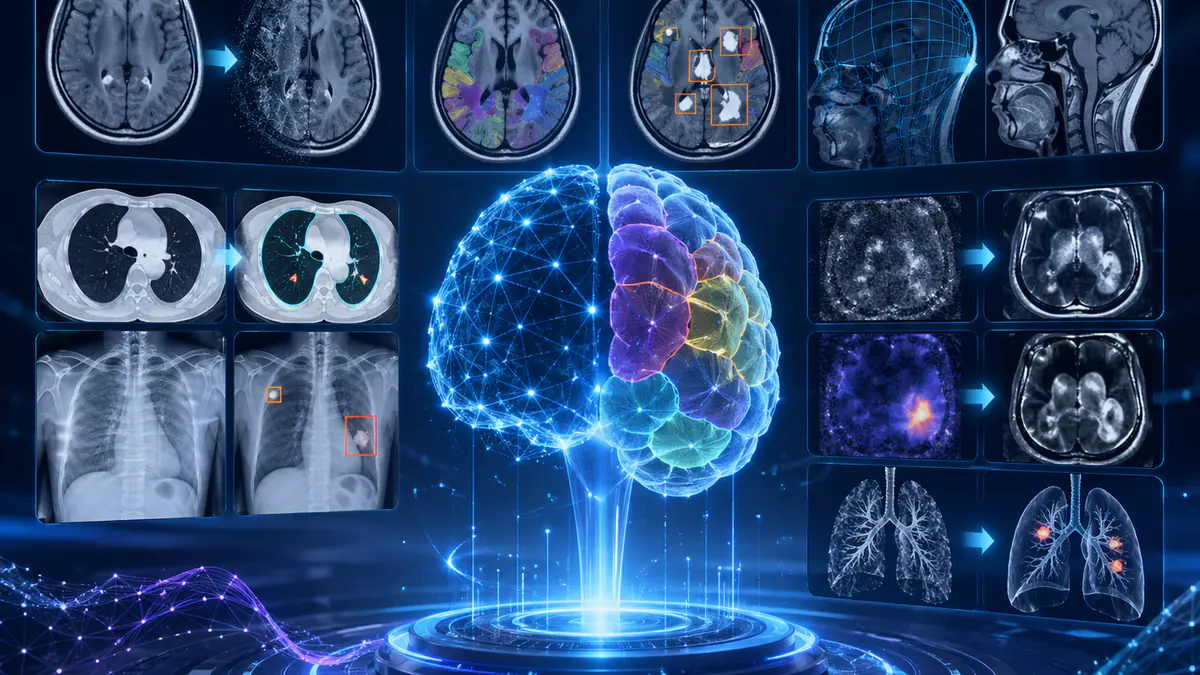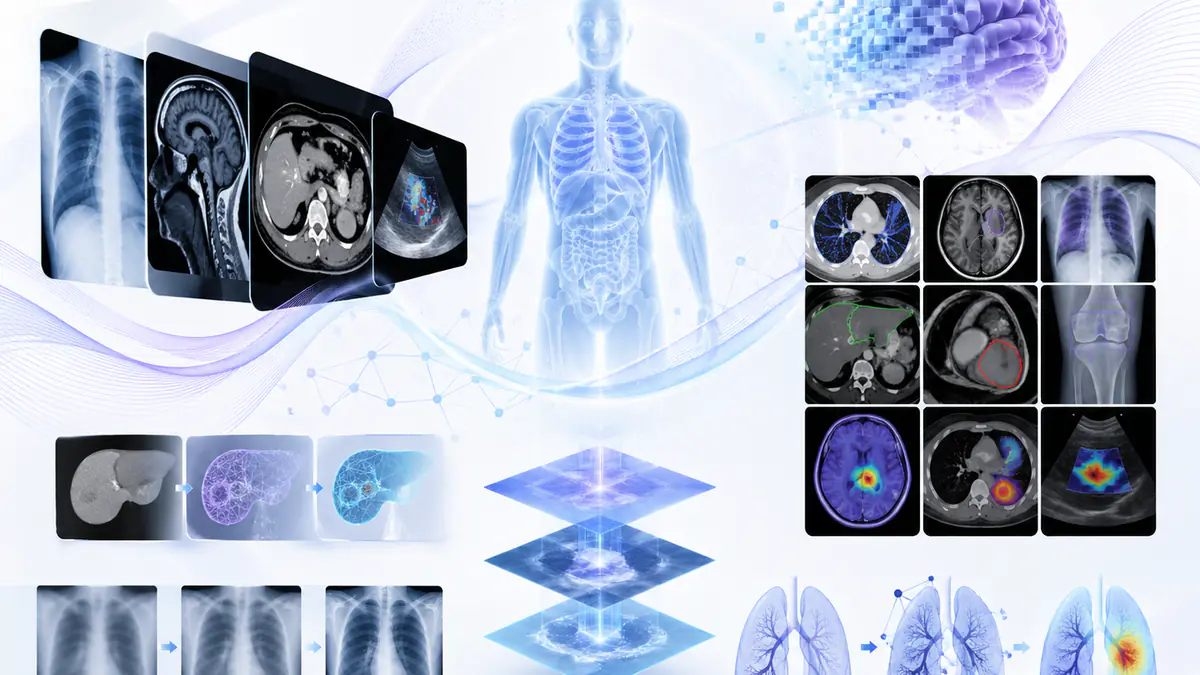
Ark+:由多套异构标注数据监督训练单一高性能 AI 基础模型,无需标签整合
Medical Image Analysis - 2026
一种面向多源异构标注数据的监督训练方法,用于训练单一高性能 AI 基础模型,避免人工标签整合。

面向医学人工智能研究者、临床团队与开发者,提供来源可追溯、结构化整理的研究资源,支持从问题发现、模型验证到临床转化的完整创新链路。
Medical Image Analysis - 2026
一种面向多源异构标注数据的监督训练方法,用于训练单一高性能 AI 基础模型,避免人工标签整合。
ICLR 2026 Poster - 2026
ICLR 2026 Poster accepted paper at ICLR 2026. The ability to distinguish subtle differences between visually similar images is essential for diverse domains such as industrial anomaly detection, medical imaging, and aerial surveillance. While comparative reasoning benchmarks for vision-language models (VLMs) have recently emerged, they primarily focus on images with large, salient differences and fail to capture the nuanced reasoning required for real-world applications. In this work, we introduce **VLM-SubtleBench**, a benchmark designed to evaluate VLMs on *subtle comparative reasoning*. Our benchmark covers ten difference types—Attribute, State, Emotion, Temporal, Spatial, Existence, Quantity, Quality, Viewpoint, and Action—and curate paired question–image sets reflecting these fine-grained variations.
ICLR 2026 Poster - 2026
ICLR 2026 Poster accepted paper at ICLR 2026. Typographic attacks exploit multi-modal systems by injecting text into images, leading to targeted misclassifications, malicious content generation and even Vision-Language Model jailbreaks. In this work, we analyze how CLIP vision encoders behave under typographic attacks, locating specialized attention heads in the latter half of the model's layers that causally extract and transmit typographic information to the cls token. Building on these insights, we introduce Dyslexify - a method to defend CLIP models against typographic attacks by selectively ablating a typographic circuit, consisting of attention heads. Without requiring finetuning, dyslexify improves performance by up to 22.06\% on a typographic variant of ImageNet-100, while reducing standard ImageNet-100 accuracy by less than 1\%, and demonstrate its utility in a medical foundation model for skin lesion diagnosis.
 critical care time-series variables and outcomes
critical care time-series variables and outcomesICU time-series benchmark dataset
The PhysioNet/CinC Challenge 2012 dataset contains ICU time-series records used for mortality prediction and patient-specific outcome modeling. It remains a useful benchmark for clinical time-series modeling, missingness-aware learning, and early warning model development.
 Chinese community medical questions and answers
Chinese community medical questions and answersChinese medical QA dataset
cMedQA2 is an updated Chinese community medical question answering dataset for question-answer matching and medical QA research. It is useful for training and evaluating Chinese medical retrieval, ranking, and answer selection models.
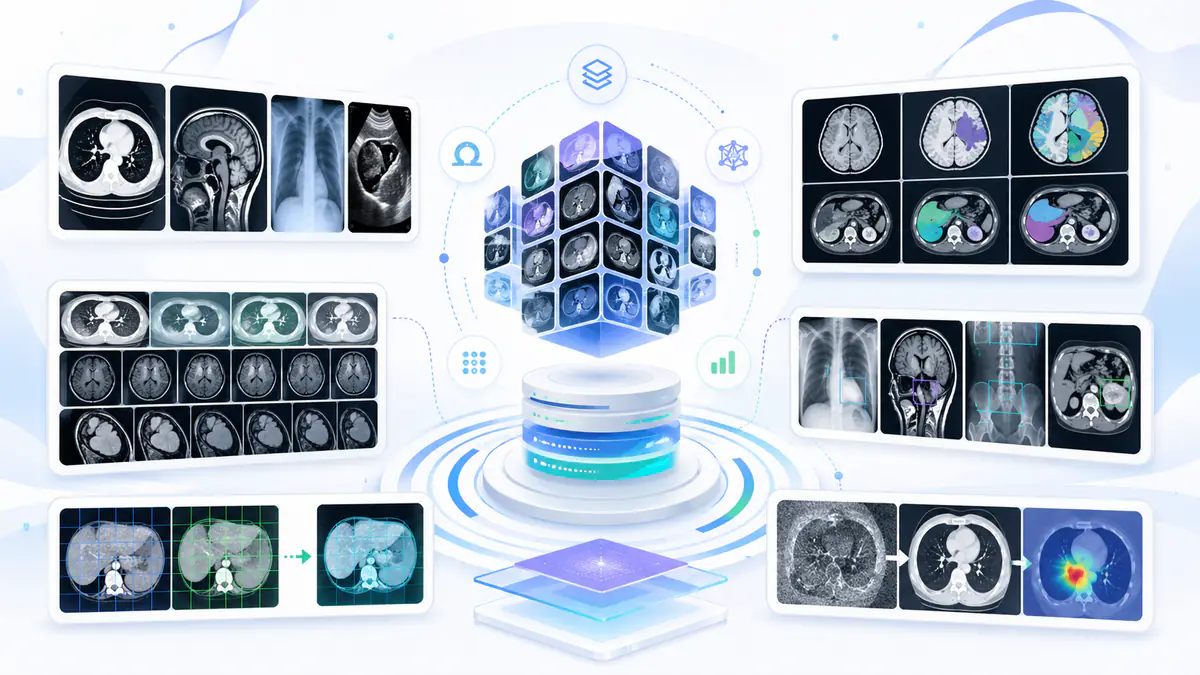 abdominal CT and MRI with multi-organ annotations
abdominal CT and MRI with multi-organ annotationsabdominal multi-organ segmentation benchmark
AMOS is an abdominal multi-organ segmentation benchmark with CT and MRI cases for evaluating versatile medical image segmentation models. It supports abdominal organ segmentation, modality-general segmentation, and benchmarking of robust 3D segmentation methods.